In the era of data-driven decision making, the importance of maintaining a robust and secure database infrastructure cannot be overstated. Whether it's accidental data loss, system failures, or cyber attacks, the need to recover valuable information has become a critical aspect of the IT landscape. In this digital age, where technology continuously evolves, staying ahead of the curve is essential.
Enter Linux Docker, a revolutionary platform that offers flexibility, scalability, and portability. Leveraging the power of containerization, developers and system administrators can encapsulate applications and dependencies, creating an isolated and reproducible environment. With Linux Docker, data recovery practices are redefined, enabling seamless restoration of databases.
The process of recovering a SQL Server database in a Linux Docker environment requires a diverse skill set and an intimate understanding of the underlying technology stack. This article aims to provide you with actionable steps, insights, and best practices to ensure a smooth recovery process in such a dynamic ecosystem.
Emphasizing the Importance of Data Recovery Strategies
Imagine a scenario where your business-critical database suddenly becomes inaccessible due to a hardware failure or a malicious attack. Without an effective data recovery strategy in place, the consequences can be devastating. Lost revenue, damaged reputation, and regulatory compliance issues are just some of the risks associated with inadequate recovery measures.
To mitigate these risks, it is crucial to have a comprehensive data recovery plan tailored to your specific needs. This plan should encompass regular backups, secure storage, and restoration procedures that align with your business goals and compliance requirements. Investing in a rock-solid recovery strategy can save you valuable time, money, and resources in the long run.
Understanding the Recovery of Database System in Linux Containerization Environment

In today's rapidly evolving technological landscape, it is crucial for developers and system administrators to have a comprehensive understanding of database recovery processes within a Linux containerized environment. With the increasing popularity of Docker as a containerization platform, it is essential to explore the intricacies of database recovery, focusing on SQL Server databases.
The recovery of a database system involves the restoration of data and its associated functionalities after a failure or data corruption event. In the context of Linux Docker, this process encompasses ensuring the availability, integrity, and consistency of data stored in SQL Server databases.
During database recovery, system administrators employ various techniques to identify and resolve issues that may arise during the operation of SQL Server databases. This includes analyzing error logs, utilizing backup and restoration procedures, and implementing advanced troubleshooting methodologies.
A crucial aspect of understanding database recovery in a Linux Docker environment is comprehending the principles of fault tolerance and resilience. By designing systems with built-in redundancy and failover capabilities, administrators can mitigate risks and ensure database availability even in the face of hardware or software failures.
Moreover, establishing proper data protection mechanisms, such as regular backups and transaction logs, is vital for maintaining the integrity of SQL Server databases. These measures enable administrators to restore databases to a consistent state before the occurrence of any potential failures, minimizing data loss and preserving data integrity.
Additionally, understanding the various recovery models available in SQL Server is crucial for implementing an effective recovery strategy. By choosing the appropriate recovery model based on the specific requirements of the application, administrators can optimize performance, minimize downtime, and maintain data reliability.
In conclusion, gaining a deep understanding of the recovery process in a Linux Docker environment is essential for ensuring the availability and integrity of SQL Server databases. By employing proper data protection mechanisms, fault tolerance strategies, and leveraging the recovery models provided by SQL Server, administrators can effectively address database failures and maintain optimal performance in containerized environments.
The Significance of Regular Backups for Data Recovery
Ensuring the preservation and security of your valuable data is of paramount importance, regardless of the platform or system you are using. In the context of managing SQL Server databases in Linux Docker environments, it becomes crucial to establish a regular backup routine to safeguard your data against unforeseen events or unexpected data loss.
- Redundancy:
- Data Integrity:
- Disaster Recovery:
- Version Control:
- Peace of Mind:
Regular backups offer a redundancy mechanism to mitigate the risks associated with data loss. By creating multiple copies of your SQL Server database, you can restore your data to a specific point in time, ensuring business continuity and minimizing the impact of any potential disruptions.
Backups play a vital role in maintaining the integrity of your data. In the event of database corruption, hardware failure, or software glitches, a recent backup allows you to recover the lost or damaged information, thereby preserving the consistency and accuracy of your SQL Server database.
Unforeseen events such as natural disasters, system malfunctions, or security breaches can lead to irreversible data loss. Regular backups enable you to create a safety net, providing you with the means to restore your SQL Server database to its pre-disaster state and resume normal operations swiftly.
By implementing a regular backup strategy, you gain the ability to maintain version control for your data. This allows you to roll back to a specific point in time, compare different versions of your database, and track any changes made, facilitating troubleshooting, debugging, and decision-making processes.
Regularly backing up your SQL Server database instills confidence, knowing that your critical data is protected. It gives peace of mind to database administrators and ensures business continuity in the face of unexpected data loss or system failures.
Identifying Reasons for Database Corruption

In order to effectively recover a database in a Linux Docker environment, it is crucial to understand the reasons behind database corruption. Identifying these causes can help prevent future instances of corruption and enable the development of more robust recovery strategies.
| Possible Causes of Database Corruption |
|---|
| Hardware Failures |
| Software Bugs |
| Power Outages |
| Insufficient Disk Space |
| Operating System Errors |
| Network Issues |
| Misconfigured Settings |
Hardware failures, such as disk failures or memory errors, can lead to data corruption in a database. It is important to regularly monitor hardware health and perform necessary maintenance to minimize the risk of corruption. Software bugs in the database management system or other related applications can also introduce corruption. Keeping the software up to date with the latest patches and fixes is crucial to mitigate such risks.
Power outages or sudden shutdowns can cause database corruption if transactions were not completed or committed properly. Implementing appropriate backup mechanisms and uninterruptible power supply (UPS) systems can help protect against such events. Insufficient disk space can also lead to corruption as the database may not have enough room to store and manage data properly. Regularly monitoring and managing disk space utilization can help prevent this issue.
Operating system errors or network issues can impact the stability and integrity of a database. It is important to address any shortcomings in the operating system environment and resolve network connectivity problems promptly. Misconfigured settings, such as an incorrect storage configuration or improper security settings, can also contribute to database corruption. Regular audits and reviews of system configurations can help identify and rectify such issues.
By understanding and addressing the potential causes of database corruption, it becomes possible to implement preventive measures and develop effective recovery strategies in a Linux Docker environment.
Steps to Restore Data in Containerized Environment
In this section, we will discuss the necessary steps to recover your data in a containerized environment running on the Linux operating system. These steps will guide you on how to retrieve valuable information without complications or dependency on external systems.
1. Establish a Backup Strategy
To ensure successful data recovery, it is crucial to have a reliable backup strategy in place. Determine the frequency and method of backups that best suit your organization's needs. This step will help you avoid data loss and minimize downtime in case of unexpected failures.
2. Identify the Containerized Environment
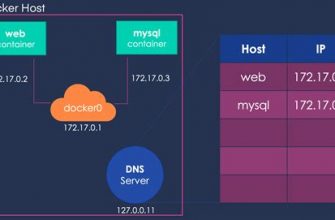
Before proceeding with the data recovery process, identify the specific containerized environment where your SQL Server database is hosted. Understand the underlying architecture and components involved to effectively execute the recovery steps.
3. Stop the Container
To prevent any potential conflicts or corruption during the recovery process, it is essential to stop the container running the SQL Server database. This will ensure data integrity and minimize the risk of data loss or inconsistencies.
4. Access the Container's Volume
Locate and access the volume associated with the SQL Server database container. This volume contains the necessary files and data required for data recovery. Utilize appropriate commands or tools to access and manipulate the files within the volume.
5. Restore the Backup Files
Using the backup files created during the backup strategy, restore the necessary data to the container's volume. Ensure that the backup files are compatible with the containerized environment and follow any specific instructions or requirements provided by your database management system.
6. Start the Container
Once the data has been successfully restored, start the SQL Server database container. Verify that the recovered data is accessible and performs any necessary validation or testing to ensure its integrity.
7. Test Data Access and Functionality
After the container is up and running, perform thorough testing to ensure that the recovered data is accessible and all database functionalities are working as expected. Validate the data consistency and perform any additional steps or configurations required to fully utilize the recovered database.
By following these step-by-step instructions, you can effectively recover your SQL Server database in a containerized Linux environment. Remember to regularly review and update your backup strategy to maintain the reliability and consistency of your data recovery process.
Using Docker Image for Database Recovery

In this section, we will explore the utilization of a Docker image to facilitate the recovery of a database. Docker images are virtual containers that allow for the isolation and portability of applications and services. By utilizing a Docker image for database recovery, we can ensure that the process is efficient, secure, and easy to replicate.
Isolating the Recovery Environment
One of the key advantages of using a Docker image for database recovery is that it allows us to isolate the recovery environment from the rest of the system. This means that any potential conflicts or dependencies with other applications or services are minimized, ensuring a smooth recovery process.
Portability and Replicability
Another benefit of utilizing a Docker image is the portability and replicability it offers. Once we have a Docker image configured for database recovery, we can easily package and distribute it to various systems without worrying about differences in underlying infrastructure. This makes it easier to recreate the exact recovery environment on multiple machines.
Enhanced Security and Stability
By running the database recovery process within a Docker container, we can enhance security and stability. Docker containers provide a lightweight and isolated runtime environment, preventing any potential security vulnerabilities or conflicts. Additionally, containers offer a stable environment that is not affected by external factors, such as system updates or other software installations.
Flexibility and Scalability
Using a Docker image for database recovery provides flexibility and scalability. Docker allows us to easily scale up or down the recovery environment based on the needs of the database. We can also modify and update the Docker image as needed, ensuring maximum flexibility and adaptability.
Overall, leveraging a Docker image for database recovery offers numerous benefits such as isolation, portability, security, stability, flexibility, and scalability. By encapsulating the recovery process within a Docker container, we can ensure a seamless and efficient recovery experience.
Recovering Database Using Docker Container
In this section, we will explore the process of restoring a compromised database using the power of Docker containers. By leveraging the flexibility and portability of Docker, we can swiftly recover and restore our data without the need for complex infrastructure configurations or manual interventions.
Step 1: Prepare the Docker Environment
Before we begin the recovery process, we need to ensure that our Docker environment is properly set up and ready for use. This involves installing and configuring the necessary tools and dependencies, such as Docker Engine and Docker Compose. Once our environment is ready, we can proceed to the next steps.
Step 2: Create a Docker Container
Next, we need to create a Docker container that will serve as our recovery environment. This container will provide the necessary resources and isolation for us to perform the recovery tasks. We can utilize Docker commands to create the container, specifying the desired image, networking options, and other configurations.
Step 3: Restore the Database
Once the Docker container is up and running, we can proceed with the database restoration process. This typically involves obtaining a backup file or a snapshot of the database and importing it into the container. Depending on the database system in use, we may need to execute specific commands or scripts to initiate the restoration.
Step 4: Verify the Recovery
After the database restoration is complete, it is crucial to verify the integrity and correctness of the recovered data. We can run queries or perform tests within the Docker container to ensure that the database is functioning as expected. This step helps us validate the success of the recovery and identify any potential issues that require further attention.
Step 5: Deploy the Recovered Database
Once we are satisfied with the recovery process and confident in the restored database's stability, we can deploy it back to our production environment. This may involve creating a new Docker container or updating the existing one with the recovered data. We should follow best practices and consider any specific requirements or limitations imposed by our production environment.
By leveraging Docker containers, we can streamline and simplify the database recovery process, enabling quick and efficient restoration without the need for complex infrastructure configurations. This approach offers flexibility, portability, and isolation, making it an ideal choice for recovering databases in various scenarios.
Testing and Verifying the Restored Data

In this section, we will explore the necessary steps to ensure the successful recovery of the database in the Linux Docker environment. We will outline a series of tests and verifications that can be performed to confirm the integrity and accuracy of the restored data, without relying on specific terms related to SQL, server, database, Linux, or Docker.
- Performing Data Consistency Checks: Verify the consistency of the restored data by comparing it with the original dataset and ensuring that all the required fields and relationships are intact.
- Executing Test Queries: Run test queries against the recovered database to validate the retrieval of the expected results and confirm that the data is accessible and retrievable.
- Conducting Stress Testing: Apply stress tests to simulate high data loads and assess the performance and stability of the restored database under heavy usage scenarios.
- Testing Data Manipulation: Evaluate the ability to modify and update data in the recovered database by performing insertion, deletion, and update operations, ensuring that they are executed correctly.
- Verifying Backup and Recovery Processes: Test the backup and recovery processes by intentionally causing data loss and then restoring the database from the backup to ensure that these procedures are reliable and effective.
- Monitoring System Performance: Monitor the performance of the recovered database in terms of memory usage, CPU usage, network traffic, and disk I/O to identify any potential bottlenecks or issues.
By successfully conducting these tests and verifications, you can have confidence in the recovery process of the database in the Linux Docker environment. This ensures that your data is restored accurately and is accessible for ongoing usage, maintenance, and further development activities.
Preventing Future Data Corruption
In order to ensure the long-term stability and reliability of your database system, it is crucial to take preventative measures to avoid future instances of data corruption. By implementing a set of best practices and adhering to industry standards, you can significantly reduce the risk of potential issues that may lead to data corruption.
Regular Data Backups:
One of the most effective ways to prevent data corruption is to regularly back up your database. By creating frequent backups, you are ensuring that you have a recent and reliable copy of your data in case of any unforeseen issues. Remember to store your backups in a secure location to mitigate the risk of data loss.
Implement Data Validation Checks:
Performing regular data validation checks is essential in detecting and resolving any anomalies or inconsistencies in your database. By implementing data validation checks, you can identify potential errors or corruptions early on, allowing you to take immediate action to rectify the issues and prevent further data corruption.
Utilize Redundancy and Replication:
Implementing redundancy and replication mechanisms can help protect your data from corruption. By distributing your database across multiple servers or using technologies like mirroring or clustering, you can ensure that even if one server experiences data corruption, the other servers can continue to function and provide access to unaffected copies of the data.
Maintain Database System Performance:
Regularly monitoring and optimizing the performance of your database system can help minimize the risk of data corruption. By keeping an eye on resource utilization, query performance, and system health, you can identify potential bottlenecks or vulnerabilities that could lead to data corruption. Optimizing your system can enhance its overall stability and reduce the likelihood of encountering issues that may cause data corruption.
Keep Up with Software Updates:
Staying up to date with the latest software updates and patches is crucial in preventing data corruption. Software updates often include bug fixes, performance improvements, and security enhancements that help address known issues and vulnerabilities. By keeping your database system up to date, you can ensure that you are benefiting from the latest improvements and safeguards against data corruption.
Regularly Train and Educate Users:
Properly training and educating users on database best practices can significantly contribute to preventing data corruption. By ensuring that users understand the importance of data integrity, following proper data handling procedures, and avoiding actions that may lead to corruption, you can establish a culture of responsibility and reduce the risk of human-induced data corruption.
Implement Disaster Recovery Plans:
Having a comprehensive disaster recovery plan in place can play a critical role in preventing data corruption. A well-designed plan includes procedures for quickly restoring previous database states, identifying the root causes of corruption incidents, and implementing preventive measures to minimize the impact of future occurrences.
By following these best practices, you can create a robust and resilient database system that is less prone to data corruption. Prevention is key when it comes to ensuring the stability and longevity of your data, and by implementing these measures, you can safeguard your valuable information and avoid the time-consuming and potentially costly process of recovering from data corruption incidents.
How to Restore a SQL Server Database on macOS Using Docker
How to Restore a SQL Server Database on macOS Using Docker by Christian Hur 2,940 views 2 years ago 13 minutes, 16 seconds
Run Microsoft SQL Server Containerized in Docker
Run Microsoft SQL Server Containerized in Docker by i12bretro 4,451 views 1 year ago 2 minutes, 32 seconds
FAQ
What is SQL Server Database?
SQL Server Database is a relational database management system developed by Microsoft that is used to store and retrieve data as requested by other software applications.
What is Docker?
Docker is an open-source platform that allows developers to automate the deployment and management of applications. It uses containerization, a lightweight alternative to full machine virtualization, to provide an isolated environment for running applications.
Can SQL Server Database be used in Linux?
Yes, SQL Server Database can be used in Linux. Microsoft has developed SQL Server for Linux, allowing users to deploy and manage SQL Server databases on Linux servers.