When it comes to leveraging the power of Kafka in the Docker environment on the Windows platform, developers often encounter a multitude of hurdles and obstacles. This article aims to shed light on the difficulties that arise in deploying Kafka containers and effectively utilizing data within this setup. By exploring the intricacies of this ecosystem, we endeavor to provide potential solutions and insights for enthusiasts and professionals alike.
The integration of Kafka and Docker, while offering immense benefits such as scalability, fault tolerance, and simplified infrastructure management, poses unique challenges for Windows users. The constraints imposed by the Windows ecosystem demand meticulous attention to detail and a nuanced understanding of the underlying components involved. Without a doubt, this convergence of technologies demands the mastery of efficient workarounds and the usage of appropriate tools to ensure seamless operation.
Among the primary quandaries faced by those attempting to utilize Kafka in Docker for Windows is the complexity surrounding data handling. Be it the necessity to ensure data persistence, the intricacies of data sharing among containers, or the optimization of data flows, these challenges can impede the smooth functioning of the Kafka ecosystem. By exploring potential techniques, configurations, and best practices, this article aims to empower readers with the knowledge required to overcome these hurdles and harness the full potential of Kafka in the Docker environment on Windows.
In summary, the combination of Kafka, Docker, and the Windows platform presents an enthralling landscape for developers and enthusiasts alike. However, untangling the intricacies of these technologies and implementing them harmoniously can be a perplexing endeavor. By addressing the challenges pertaining to data utilization within this ecosystem, this article hopes to pave the way for a seamless and efficient implementation of Kafka in Docker on Windows, unlocking the extraordinary capabilities of this powerful combination.
Resolving Common Challenges with Data Handling in Kafka Deployment on Windows using Docker

In the context of running Kafka on Docker in a Windows environment, there are often encountered challenges related to data handling. This section aims to shed light on these issues and provide viable solutions that can help overcome them.
Dealing with data in a Kafka setup on Docker for Windows may present certain obstacles that users can encounter during their deployment. By understanding these common problems and learning the appropriate resolutions, users can ensure a smooth and efficient data workflow in their Kafka environment.
One common issue that arises is the inability to effectively manage and manipulate data in the Kafka ecosystem within a Docker container running on Windows. This can be due to limitations in accessing or interacting with the data stored in Kafka topics or issues with data replication and synchronization across different Kafka instances.
To resolve these challenges, it is crucial to employ strategies such as optimizing the configuration settings, ensuring proper networking connectivity, and implementing effective data management techniques. By fine-tuning the Kafka settings to align with the Windows-based Docker environment, users can mitigate data-related issues and enhance the overall performance of their Kafka deployment.
Additionally, utilizing proven techniques like data serialization and deserialization, leveraging Kafka's native tools for data management, and adopting effective monitoring and debugging practices can further aid in resolving common data handling challenges. These measures can facilitate seamless data transfer, synchronization, and maintenance within the Kafka architecture on Docker for Windows.
In summary, understanding and addressing the common data handling issues that arise in Kafka deployments on Docker for Windows is crucial for ensuring a successful and efficient Kafka setup. By implementing appropriate solutions, users can overcome these challenges and maximize the full potential of Kafka in their Windows-based Docker environments.
Troubleshooting Issue with Accessing Information
When working with the integration of Kafka in the Docker environment for Windows, there might be instances where you encounter difficulties in utilizing the available data. This section aims to address and provide solutions for the problem related to accessing information within the system.
Understanding the Architecture of Kafka Running in Docker on the Windows Platform

In this section, we will delve into a comprehensive understanding of the underlying architecture of Kafka when it is deployed within a Docker environment on the Windows platform.
Firstly, let's explore the fundamental components that make up the Kafka ecosystem. These components play a crucial role in enabling the efficient and reliable processing of data streams. They facilitate the storage, transfer, and processing of messages in a distributed manner.
- Brokers: These are the key entities responsible for handling the storage and replication of messages within Kafka. They function as the central data processing units, managing the streams of data flowing through the system.
- Topics: Topics are the different categories or channels through which messages are organized within Kafka. They act as the primary means of classifying and categorizing data, enabling efficient data retrieval and processing.
- Producers: Producers are the entities responsible for generating and publishing data to the Kafka cluster. They create and send messages to specific topics, ensuring the continuous flow of data.
- Consumers: Consumers, on the other hand, are the recipients of the data published to Kafka. They subscribe to specific topics, retrieving and processing the messages to fulfill their intended purpose.
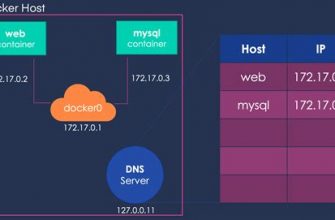
When Kafka and Docker are combined on the Windows platform, it introduces an additional layer of complexity to the architecture. Docker provides a lightweight and portable containerization solution that allows for the easy deployment and management of Kafka within a Windows environment. It enables the isolation and encapsulation of the Kafka components, ensuring a consistent and controlled runtime environment.
Within the Dockerized Kafka setup, containers are used to encapsulate each individual component of the Kafka architecture. These containers are lightweight runtime instances that provide the necessary resources and dependencies for each component to function effectively.
By utilizing Docker's containerization capabilities, developers can easily deploy and manage Kafka instances on the Windows platform without worrying about conflicting dependencies or system-specific configurations. It enables the seamless execution of Kafka in a consistent and reproducible manner, ensuring the stability and reliability of the data processing pipeline.
In conclusion, understanding the architecture of Kafka running in Docker on the Windows platform is crucial for effectively leveraging the capabilities of this powerful combination. By comprehending the underlying components and the role of Docker in facilitating the deployment and management of Kafka, developers can harness the full potential of this technology stack.
Best Practices for Configuring Kafka in Docker Environment on Windows
When working with Kafka in a Docker environment on Windows, it is essential to follow best practices to ensure smooth and efficient deployment. In this section, we will explore some recommended approaches for configuring Kafka in Docker, focusing on optimizing performance, ensuring data integrity, and enhancing overall stability.
1. Resource Allocation:
Properly allocating system resources to your Docker containers is crucial for optimal Kafka performance. Consider assigning sufficient CPU, memory, and disk space to ensure that your Kafka brokers have the necessary resources to handle the expected workload. Additionally, carefully monitor resource usage to identify and rectify any potential bottlenecks.
2. Network Configuration:
Configure your Docker network to support efficient communication between Kafka brokers and consumers. Ensure that network settings, such as port mappings and firewall rules, are properly configured to enable seamless data transfer. It is also advisable to isolate your Kafka container from other potentially resource-intensive services to prevent interference.
3. Data Persistence:
Implement proper data persistence mechanisms to ensure durability and reliability of Kafka data. Consider utilizing Docker volumes or host-mounted directories to store Kafka logs and other important data outside the container. This approach allows data to survive container restarts or failures, ensuring continuity in case of unexpected events.
4. Security Considerations:
When deploying Kafka in a Docker environment, it is crucial to prioritize security. Implement strong authentication and authorization mechanisms to protect sensitive data and ensure that only authorized entities can access Kafka resources. Additionally, regularly update your Kafka and Docker versions to leverage the latest security patches and enhancements.
5. Monitoring and Alerting:
Integrate monitoring and alerting tools to gain insights into Kafka's performance and health. Implement monitoring solutions that provide metrics on topics such as message throughput, latency, and cluster health. Set up alerts to notify administrators in case of any anomalies or potential issues, enabling proactive troubleshooting and maintenance.
Conclusion:
By following these best practices, you can optimize the configuration of Kafka in Docker on Windows, ensuring smooth data processing, high availability, and robust security. Implementing these recommendations will help you create a stable and efficient Kafka environment that can cater to the needs of your application.
Step-by-Step Instructions for Configuring Data in Kafka on Docker for Windows

In this section, we will provide a detailed guide on how to set up and configure data usage in Kafka using Docker for Windows. We will walk you through the step-by-step process of creating and managing data in Kafka, without relying on the traditional methods. By following these instructions, you will be able to seamlessly utilize data within your Kafka environment on Docker for Windows, ensuring efficient and effective data processing.
| Step | Description |
|---|---|
| 1 | Create a Docker environment |
| 2 | Set up Kafka containers |
| 3 | Configure data storage for Kafka |
| 4 | Create and manage Kafka topics |
| 5 | Produce and consume data in Kafka |
| 6 | Monitor data usage in Kafka |
By following this step-by-step guide, you will have a clear understanding of how to configure data in Kafka on Docker for Windows. These instructions will enable you to effectively utilize and manage data within your Kafka environment, ensuring its seamless integration with your applications and systems.
Diagnostic Tools for Identifying Data Usage Problems
When working with Kafka in a Docker environment on Windows, it is common to encounter issues related to data usage. These problems can hinder the smooth functioning of the application and impede the flow of data. In such cases, it becomes crucial to have access to effective diagnostic tools that can help identify and resolve these issues.
Understanding the root cause of data usage problems is essential in order to implement appropriate solutions. Diagnostic tools play a vital role in this process by providing insights into various aspects of data handling, such as data flow, storage, and processing. These tools assist in detecting bottlenecks, analyzing performance metrics, and identifying any anomalies or inefficiencies that may be affecting data usage.
One useful diagnostic tool for investigating data usage problems is a profiler. A profiler enables the collection of detailed information about the execution of the application, allowing for the identification of any slow or inefficient code that may be impacting data usage. By analyzing the profiler's output, developers can pinpoint areas for optimization and rework them to enhance the application's performance.
Another crucial diagnostic tool is a monitoring system. Monitoring tools provide real-time visibility into the application's performance and can alert developers to any abnormal patterns or events that may affect data usage. These tools help in understanding the overall health of the system by monitoring metrics such as CPU usage, memory usage, network traffic, and disk I/O. By utilizing a monitoring system, developers can proactively identify and address any issues that may arise with data usage.
Additionally, log analysis tools can aid in the diagnosis of data usage problems. By examining log files generated by the application, developers can gain insights into the sequence of events and identify any errors or warnings that may be impacting data flow. Log analysis tools empower developers to trace the path of data through the application and identify potential bottlenecks or issues that may be affecting data usage.
In conclusion, diagnostic tools are indispensable in identifying and resolving data usage problems when working with Kafka in a Docker environment on Windows. Profilers, monitoring systems, and log analysis tools provide valuable insights into the application's performance, enabling developers to optimize and enhance data usage by addressing bottlenecks and inefficiencies.
Resolving Data Connection Issues in Kafka Docker Container

In this section, we will explore strategies for troubleshooting and resolving data connection problems that may arise when running a Kafka container in Docker for Windows. These issues can hinder the proper functioning of the Kafka instance and disrupt data processing and communication within the system. By identifying the root causes and applying appropriate solutions, we can ensure a smooth and uninterrupted flow of data.
- Check Network Configurations: Investigate the network settings of the Docker environment to ensure that they align with the requirements of Kafka. Verify that the necessary ports are open and accessible both within the container and externally.
- Verify Container Connectivity: Ensure that the Kafka container has access to the network and can communicate with other components within the system. Use network diagnostic tools to test connectivity and identify any potential issues.
- Inspect Host Firewall: Examine the firewall settings on the host machine to verify that they allow incoming and outgoing connections to the Kafka container. Adjust the firewall rules if necessary to enable uninterrupted data flow.
- Validate Data Source Configuration: Double-check the configuration settings for the data source connected to Kafka. Ensure that the correct address, port, and authentication credentials are specified to establish a successful connection.
- Review Kafka Container Logs: Analyze the logs generated by the Kafka container to identify any error messages or warnings related to data connection. These logs can provide valuable insights into the underlying issues and guide the troubleshooting process.
- Restart Containers and Services: Sometimes, simple restarts of the Kafka container and associated services can resolve data connection problems. Restarting can help reset network connections and clear any temporary issues that may have been affecting data transfer.
- Collaborate with Community: If the data connection issues persist and the troubleshooting steps mentioned here do not resolve the problem, consider reaching out to the Kafka community for assistance. Online forums, mailing lists, and developer communities can provide additional guidance and insights into more specific and complex scenarios.
By following these steps and applying the appropriate solutions, you can effectively resolve data connection issues in a Kafka Docker container running on Windows. Ensuring a robust and reliable data connection is crucial for the seamless operation of Kafka and the uninterrupted flow of data within your system.
Optimizing Performance: Tips for Efficient Data Usage in Kafka Docker Setup
In order to maximize the performance and efficiency of your Kafka Docker setup, it is essential to implement techniques that optimize data usage. By adopting these strategies, users can minimize resource consumption, reduce latency, and improve overall system performance.
1. Streamlining Data Flow:
Efficient data usage can be achieved by streamlining the flow of information within the Kafka Docker setup. This involves designing well-structured data pipelines and minimizing unnecessary data transformations. By reducing the number of intermediate steps and ensuring proper data organization, users can improve processing speed and reduce data redundancy.
2. Implementing Data Compression:
Data compression is an effective technique for optimizing storage and network resources within a Kafka Docker setup. By compressing data before it is sent through Kafka topics, users can significantly reduce the amount of disk space and network bandwidth required. Utilizing efficient compression algorithms, such as Gzip or Snappy, can help achieve better data compression ratios with minimal impact on processing speed.
3. Fine-tuning Kafka Configuration:
To maximize performance, it is important to fine-tune Kafka's configuration parameters based on the specific needs of your Docker setup. By adjusting parameters such as batch size, replication factor, and buffer sizes, users can optimize data throughput and minimize resource contention. Monitoring Kafka's performance metrics and making appropriate configuration changes will ensure efficient data usage.
4. Utilizing Data Partitioning:
Data partitioning plays a crucial role in achieving efficient data distribution and load balancing in a Kafka Docker setup. By partitioning data across multiple brokers, users can distribute the workload evenly and improve overall system performance. Carefully choosing the number of partitions based on the data volume and anticipated traffic patterns can help optimize data usage and prevent bottlenecks.
5. Performing Regular Data Maintenance:
Regular data maintenance tasks, such as purging unnecessary data, compacting and optimizing log segments, and monitoring disk usage, are essential for efficient data usage in a Kafka Docker setup. By removing obsolete or expired data, users can free up resources and ensure optimal performance. Implementing proper data retention policies and scheduling regular maintenance tasks will help maintain an efficient and well-performing Kafka environment.
In conclusion, by implementing these tips for efficient data usage in a Kafka Docker setup, users can optimize performance, reduce resource consumption, and ensure smooth operation of their Kafka-based applications.
Kafka in 100 Seconds
Kafka in 100 Seconds by Fireship 777,510 views 1 year ago 2 minutes, 35 seconds
How to Install Kafka Using Docker - Write Your First Kafka Topic | Better Data Science
How to Install Kafka Using Docker - Write Your First Kafka Topic | Better Data Science by Better Data Science 27,503 views 2 years ago 12 minutes, 35 seconds
FAQ
What is the issue with using data in Kafka in Docker for Windows?
The issue with using data in Kafka in Docker for Windows arises when the container is stopped or restarted. By default, Docker containers in Windows use a virtualized filesystem, and any changes made inside the container are not persisted. This means that any data generated or modified in Kafka while running in a Docker container will be lost once the container is stopped or restarted.
How can I solve the problem of losing data in Kafka in Docker for Windows?
To solve the problem of losing data in Kafka in Docker for Windows, you can use Docker volumes. Docker volumes allow you to create a separate storage location outside the container that can persist data even when the container is stopped or restarted. By mounting a volume to the Kafka container, you can ensure that any data generated or modified in Kafka is stored in the volume and can be accessed later even after container restarts.
Can I use Docker volumes with Kafka in Docker for Windows?
Yes, you can use Docker volumes with Kafka in Docker for Windows to persist data. By mounting a volume to the Kafka container, you can ensure that any data generated or modified in Kafka is stored in the volume and can be accessed later even after container restarts. This allows you to use and maintain data in Kafka containers without worrying about losing it when the container is stopped or restarted.