Are you looking to create powerful and efficient web scrapers to gather valuable data for your business? Look no further! In this article, we will guide you through the process of setting up Scrapy, a versatile and high-performance web scraping framework, on your Windows Server 2019 environment. But wait, there's more - we won't just stop there! We will take it a step further by deploying Scrapy within a Docker container, enabling seamless scalability and easy management of your scraping project.
Introducing Scrapy, a remarkable open-source framework that empowers developers and data enthusiasts alike to extract structured data from websites. It offers immense flexibility and robustness, making it the go-to choice for web scraping projects of any scale. Whether you're extracting information, monitoring websites, or conducting research, Scrapy provides an arsenal of powerful features to simplify the process and deliver accurate results.
But how do you get Scrapy up and running on your Windows Server 2019? That's where Docker comes into play. Docker allows you to package applications, along with their dependencies, into virtualized containers that can be easily deployed across various environments. By utilizing Docker containers, you can eliminate the hassle of dealing with complex software installations and compatibility issues. Instead, you can focus on unleashing Scrapy's full potential in an isolated and streamlined manner.
Join us on this journey as we dive deep into the installation process and explore the benefits of running Scrapy within a Docker container on your Windows Server 2019 environment. We will walk you through each step, ensuring that you have the necessary tools and knowledge to embark on your web scraping adventure. So let's roll up our sleeves and unlock the power of Scrapy, combined with the convenience of Docker containers, to effortlessly gather the data your business needs!
Introduction to Scrapy: An Efficient Web Crawling and Scraping Framework

Scrapy, a powerful Python library, offers a plethora of capabilities when it comes to web crawling and scraping tasks. This versatile framework empowers developers with the ability to extract structured data from websites efficiently and effortlessly. With Scrapy, you can easily navigate through websites, collect data, and store it in a structured manner for further analysis and processing.
Scrapy leverages its robust and flexible architecture to handle the complexities of web crawling and scraping, enabling developers to build scalable and customizable web spiders. These web spiders can intelligently navigate websites, follow links, and gather data from multiple pages simultaneously. By utilizing various techniques like XPath and CSS selectors, Scrapy allows you to extract specific data elements, making it a versatile tool for a wide range of web scraping tasks.
Moreover, Scrapy provides features like automatic request throttling, intelligent cookie and session handling, and powerful error handling mechanisms, which enhance the efficiency and reliability of your web scraping projects. Additionally, Scrapy is equipped with a comprehensive documentation and an active community, ensuring ample support and resources for developers using this framework.
| Key Features of Scrapy | Benefits |
|---|---|
| Robust and scalable architecture | Efficiently handle large-scale web scraping projects |
| Integrated support for XPath and CSS selectors | Extract specific data elements with ease |
| Automatic request throttling and intelligent cookie handling | Ensure smooth and reliable data extraction |
| Extensive documentation and community support | Ample resources and assistance for developers |
Whether you need to scrape data for research, monitoring, or building your own dataset, Scrapy offers an efficient and powerful solution. Its versatility, ease of use, and extensive set of features make it a top choice for web scraping projects.
Introduction to Docker: Revolutionizing Application Deployment
In today's rapidly evolving software development landscape, efficient application deployment has become a fundamental need for businesses across various industries. Docker, a powerful containerization platform, has emerged as a game-changer in this regard.
Docker offers a lightweight and secure way to package applications along with their dependencies into self-contained units called containers. These containers provide an isolated environment that guarantees consistent performance across different computing environments, including Windows Server 2019.
By utilizing Docker, developers and system administrators can overcome the common challenges related to software dependencies, compatibility, and scalability. Moreover, Docker provides a standardized and streamlined approach to application deployment, making it easier to manage, scale, and update applications across different servers.
With Docker, you can take advantage of its modular and portable architecture, allowing you to seamlessly move applications between different environments, such as development, testing, and production. This flexibility eliminates the need for time-consuming and error-prone manual configurations, ensuring consistent behavior across all stages of the application lifecycle.
In addition to these benefits, Docker also promotes collaboration and innovation by enabling the creation and sharing of pre-configured containers through its vast repository of public images. These images serve as a starting point for building customized containers, saving time and effort in the development process.
Overall, Docker revolutionizes application deployment by providing a scalable, flexible, and efficient solution that simplifies the process of managing and deploying applications. Its widespread adoption within the industry is a testament to its effectiveness in addressing the challenges associated with software deployment in contemporary computing environments.
Step 1: Setting Up Docker Environment for Your Windows 2019 Machine

In order to begin the installation process of Scrapy on your Windows Server 2019 machine, it is essential to first install and configure Docker. Docker provides a lightweight and isolated environment for running applications, making it an ideal choice for deploying Scrapy.
In this step, we will guide you through the process of setting up Docker on your Windows Server 2019. By following the steps outlined below, you will ensure that your machine is ready to run Scrapy in a Docker container.
| Step | Description |
|---|---|
| Step 1.1 | Download and Install Docker Desktop for Windows. |
| Step 1.2 | Launch Docker Desktop. |
| Step 1.3 | Configure Docker settings to allocate system resources. |
| Step 1.4 | Verify Docker installation by running a simple container. |
By completing these steps, you will successfully set up Docker on your Windows Server 2019 machine, paving the way for installing Scrapy and utilizing its powerful web scraping capabilities in a controlled and efficient containerized environment.
Preconditions for Setting Up Docker Environment
Before proceeding with the installation of Scrapy on a Windows Server 2019 in a Docker Container, certain prerequisites need to be fulfilled. These requirements will ensure that Docker can be properly installed and set up on your system.
- Windows Server 2019 operating system
- Administrator access to the Windows Server
- An active internet connection to download Docker components and images
- Enough disk space to accommodate Docker components and containers
- Virtualization support enabled in the BIOS settings
- Latest version of Docker Engine
It is imperative to have a suitable operating system, such as Windows Server 2019, on which Docker can be installed. Administrator access is essential for executing administrative tasks during the Docker setup process. Additionally, a stable internet connection is required to download necessary Docker components and container images.
Sufficient disk space is crucial since Docker requires storage for its components and the containers created within. Furthermore, enabling virtualization support in the BIOS settings is necessary for Docker to function effectively. Finally, ensure that the latest version of Docker Engine is available before proceeding with the installation process.
Setting up Docker on the Latest Windows Operating System

In this section, we will provide a step-by-step installation guide for running Docker on the latest edition of the popular Windows operating system. By following these detailed instructions, you will be able to easily set up and configure Docker, which is a powerful containerization platform that allows you to run applications in isolated and portable containers.
Begin by installing Docker on your Windows Server 2019 system. Docker provides a seamless and efficient way to deploy and manage applications using containerization technology. By utilizing Docker, you can take advantage of the flexibility and scalability it offers, enabling faster application deployment and improved resource utilization.
Next, we will guide you through the process of configuring Docker on your Windows Server 2019 system. This will involve setting up the necessary prerequisites and configuring important Docker settings to ensure optimal performance and compatibility.
Once Docker is successfully installed and configured, we will walk you through the process of creating and running your first Docker container. This will allow you to experience the power and convenience of containerization firsthand, as you will be able to encapsulate your applications and their dependencies in portable Docker containers.
Finally, we will provide some additional tips and best practices for working with Docker on Windows Server 2019. This will include guidance on managing and monitoring Docker containers, as well as pointers for troubleshooting common issues that you may encounter during your Docker journey.
By the end of this step-by-step installation guide, you will have a solid understanding of Docker and its capabilities on Windows Server 2019. Armed with this knowledge, you will be well-equipped to leverage Docker's containerization technology to streamline your application deployment and enhance your overall development workflow.
Step 2: Set Up a Docker Environment
Once you have ensured the successful installation of the necessary components in Step 1, it is time to move on to creating a dedicated environment for Docker.
In this section, we will guide you through the process of configuring Docker on your system. By setting up a Docker environment, you will have a platform to run and manage your containers efficiently.
1. Install Docker: To start, you need to download and install Docker on your Windows Server 2019. Docker provides a simple and streamlined way to package and distribute applications in isolated containers.
2. Configure Docker: After installation, it is crucial to properly configure Docker. This step involves adjusting settings, such as resource allocation and network configuration, to optimize container performance.
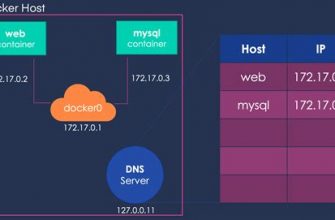
3. Create a Docker Network: In order for containers to communicate with each other, it is essential to create a dedicated Docker network. This network will enable seamless interaction and data sharing among containers within the same environment.
4. Pull Docker Images: Docker images serve as templates for creating containers. In this step, you will fetch the necessary images from a Docker registry to be used in the creation of your desired containers.
5. Create a Docker Container: Once your Docker environment is properly set up, it's time to create a container. This involves specifying the desired image, configuring relevant settings, and ensuring the container is ready to run your Scrapy application.
By carefully following these steps, you will establish a solid foundation for running your Scrapy application smoothly within a Docker environment on your Windows Server 2019.
Choosing the Right Scrapy Image

In this section, we will explore the various options available when selecting a Scrapy image for your Docker container. We will discuss the different factors to consider and guide you in making an informed decision.
- 1. Evaluating Features: Understand the unique features and capabilities offered by different Scrapy images. Look for specific functionalities that align with your project requirements.
- 2. Community Support: Consider the level of community support available for the Scrapy image you choose. A strong community can provide valuable resources, documentation, and assistance when troubleshooting issues.
- 3. Version Compatibility: Ensure that the Scrapy image you select is compatible with the version of Scrapy you intend to use. Compatibility is crucial to ensure smooth execution of your web scraping tasks.
- 4. Image Size: Take into account the size of the Scrapy image. A smaller image size can result in faster container build times and more efficient resource utilization.
- 5. Security Updates: Regularly updated Scrapy images can offer improved security by addressing vulnerabilities and addressing any potential risks associated with outdated dependencies.
- 6. User Reviews: Consider user reviews and feedback on the Scrapy image you are considering. Learning from the experiences of others can help you avoid potential pitfalls and make an informed decision.
By carefully evaluating these factors, you can choose the Scrapy image that best fits your needs, ensuring a smooth and efficient web scraping experience within your Docker container.
Creating the Docker Instance
One crucial step in setting up Scrapy on a Windows Server 2019 platform is to create a Docker instance. This process involves running a specific command to deploy a virtual environment where Scrapy and its dependencies can be installed and executed.
To start, open the command prompt on your Windows Server and navigate to the desired location where you want to create the Docker container. Once there, a specific command needs to be executed to initiate the Docker instance. This command will create a secure and isolated environment, enabling the installation and execution of Scrapy without interfering with the underlying server or other applications.
By running the Docker command, you are essentially creating a lightweight, self-contained environment that can be easily managed and deployed. This approach ensures consistency across different operating systems and simplifies the process of setting up Scrapy on Windows Server 2019.
Make sure to specify any necessary parameters or flags when executing the command to create the Docker container. These may include options like network configurations, port mappings, and resource allocation, depending on your specific requirements.
Once the Docker instance is successfully created, you can proceed with installing Scrapy and configuring the necessary components within the container. This includes installing Python, setting up virtual environments, and installing any additional dependencies required for your Scrapy project.
In conclusion, creating a Docker container is a crucial step in setting up Scrapy on a Windows Server 2019 platform. This process establishes an isolated environment where Scrapy and its dependencies can be installed and executed without impacting the underlying server or other applications. By following the appropriate command syntax and including any necessary parameters, you can successfully create a Docker instance to facilitate the installation and usage of Scrapy.
Step 3: Set Up Scrapy within the Docker Environment

In this section, we will walk you through the process of configuring Scrapy within the Docker environment. By following these steps, you will be ready to start building and running Scrapy spiders for your web scraping projects.
| Step | Description |
| 1 | Create a Dockerfile |
| 2 | Define the base image |
| 3 | Install the necessary packages |
| 4 | Copy the Scrapy project files |
| 5 | Update the project settings |
| 6 | Build the Docker image |
| 7 | Run the Docker container |
Let's go through each step in detail:
Step 1: Create a Dockerfile
To set up Scrapy within the Docker environment, we need to create a Dockerfile. This file will define the configuration and dependencies for our Docker image. We will use this Dockerfile to build the image later on.
Step 2: Define the base image
In this step, we need to specify the base image we want to use for our Scrapy project. The base image provides the initial environment and tools required to run our Scrapy spiders. We can choose a lightweight base image such as Alpine or a more comprehensive one like Ubuntu.
Step 3: Install the necessary packages
In order to run Scrapy, we need to install the required packages and dependencies. This may include Python, pip, and other libraries necessary for Scrapy to function properly. We will specify these packages in the Dockerfile and ensure they are installed within the Docker environment.
Step 4: Copy the Scrapy project files
In this step, we will copy the Scrapy project files into the Docker image. This includes the spider scripts, item pipelines, and any other project-specific files. By copying these files, we ensure that the Docker environment has access to all the necessary components of our Scrapy project.
Step 5: Update the project settings
In order for Scrapy to work correctly within the Docker environment, we may need to update the project settings. This could include modifying the scrapy.cfg file or any other configuration files specific to our project. By updating the settings, we ensure that Scrapy operates smoothly within the Docker container.
Step 6: Build the Docker image
With all the necessary configurations and files in place, we can now build the Docker image. This process involves executing the Docker build command and specifying the necessary parameters. The build process may take some time, depending on the size of your project and the complexity of the dependencies.
Step 7: Run the Docker container
Finally, we can run the Docker container and start using Scrapy within the Docker environment. By running the container, we create an isolated environment where Scrapy can execute our web scraping tasks. We can interact with the container and run Scrapy commands just as we would in a traditional non-Docker environment.
Following these steps will allow you to successfully set up Scrapy within a Docker container, providing you with a reliable and portable environment for running your web scraping projects.
Accessing the Shell Inside a Docker Container
Exploring the Inner Workings
Once you have successfully set up Scrapy in a Docker container running on your Windows Server 2019 environment, you might find yourself wondering how to access the shell inside the container. This section will guide you through the process of accessing and interacting with the Docker container's shell, enabling you to gain deeper insights into its inner workings.
Unlocking the Hidden Door
To access the Docker container shell, you can make use of the exec command provided by Docker. This command allows you to execute a command inside a running container, giving you access to a shell prompt. By utilizing this command, you can navigate inside the container, inspect its file structure, and execute various system commands.
Opening Pandora's Box
In order to enter the shell of a Docker container, simply open your command prompt or terminal and enter the following Docker command:
docker exec -it [container_name_or_id] /bin/bash
Replace [container_name_or_id] with the actual name or ID of your Docker container. This command will instruct Docker to execute the Bash shell inside the specified container, granting you access to the command line interface of the container's operating system.
A Whole New World
Once inside the Docker container shell, you can utilize various shell commands to navigate through directories, view file contents, install additional software packages, and much more. This opens up a whole new world of possibilities for exploration and customization within your Docker container.
Proceed with Caution
While accessing the shell inside a Docker container provides powerful capabilities, it is important to exercise caution and be mindful of the changes you make. Any modifications made within the container's shell will persist only for the duration of the container's runtime and will not affect the underlying image or future container instances.
Step-by-Step Guide to Add Scrapy to Your Development Environment

In this section, we will walk you through the process of setting up Scrapy, a powerful web scraping framework, to enhance your development environment with its extensive features.
Firstly, it is important to note that the installation process for Scrapy is straightforward and can be completed in a few simple steps. By following the commands provided below, you will be able to seamlessly integrate Scrapy into your development environment.
1. Preparing the Environment
Before installing Scrapy, it is essential to ensure that your development environment has the necessary prerequisites. This involves verifying the presence of the required dependencies, such as Python and its associated tools.
Prior to initiating the Scrapy installation, double-check that Python is properly installed on your computer by running the following command in your terminal:
python --version2. Installing Scrapy
With the environment ready, it is now time to install Scrapy itself. Achieving this can be done conveniently via package managers such as pip, offering a streamlined process for obtaining and managing Python packages.
To begin the installation of Scrapy, execute the following command in your terminal:
pip install scrapyOnce the installation completes successfully, you are now equipped with the full functionality of Scrapy. It is recommended to verify the installation by running the following command:
scrapy --version3. Getting Started with Scrapy
Now that Scrapy is installed, you can start utilizing its remarkable features for web scraping and crawling tasks. Familiarize yourself with the Scrapy documentation and its comprehensive guides to gain a deeper understanding of the framework's capabilities and unleash the power it offers.
With these steps completed, you are now ready to begin harnessing the potential of Scrapy, leveraging its vast array of tools to streamline your web scraping endeavors.
FAQ
Can Scrapy be installed on Windows Server 2019?
Yes, Scrapy can be installed on Windows Server 2019 in a Docker container.
What is Scrapy?
Scrapy is an open-source Python framework used for web scraping and extracting structured data from websites.
Why would I need to install Scrapy on Windows Server 2019?
You may need to install Scrapy on Windows Server 2019 if you want to automate web scraping tasks and extract data without manual intervention.
What is Docker?
Docker is an open-source platform that allows you to automate the deployment and management of applications inside software containers, providing an isolated environment for running applications.
How can I install Scrapy in a Docker container on Windows Server 2019?
To install Scrapy in a Docker container on Windows Server 2019, you need to set up Docker on your server, create a Dockerfile with the necessary configurations, build the Docker image, and then run the container with the Scrapy installation.