Are you looking to optimize your data processing capabilities and enhance the efficiency of your PC? Look no further! In this article, we will guide you through the process of setting up a cutting-edge data processing environment using the power of Docker on your Windows system.
Imagine a world where you can effortlessly handle massive volumes of data, analyze it with lightning-fast speed, and extract valuable insights in no time. With the help of Docker, a powerful virtualization platform, this dream can become a reality. Whether you are a small business owner, a data analyst, or an aspiring data scientist, harnessing the potential of Docker will revolutionize the way you work with data.
By deploying a Docker-based environment to process your data, you can eliminate the need for complex configurations and time-consuming setup processes. Docker provides a seamless and efficient solution that encapsulates your data processing tools and dependencies into isolated containers, ensuring that your resources are utilized optimally without any interference from other applications.
Installing Docker on a Windows Environment

When preparing your system to use containerization technology on a Windows operating system, you will need to install Docker. Docker allows you to create and manage containers, which are lightweight and isolated environments that can run applications and services.
To get started, you will need to download and install Docker on your Windows machine. Docker provides a user-friendly installation process that can be completed in a few simple steps. Once installed, Docker will be accessible from your command line interface.
Before proceeding with the installation, make sure your Windows version meets the system requirements for running Docker. Additionally, ensure that any virtualization technology, such as Hyper-V, is enabled on your machine.
To install Docker, visit the official Docker website and download the Windows version of the Docker Desktop application. Run the installer and follow the on-screen instructions to complete the installation process.
Once Docker is successfully installed, you can verify its installation by opening a command prompt and running the command docker --version. This will display the version of Docker that has been installed on your system.
In conclusion, installing Docker on a Windows environment is a crucial step to enable containerization technology on your machine. By following the provided instructions, you can install Docker confidently and begin utilizing the benefits of containerization.
Preparing the Environment for a Distributed Data Processing System
In order to create a robust and efficient distributed data processing system, a solid foundation must be established by preparing the environment. This involves ensuring that the necessary resources, dependencies, and configurations are in place to support the smooth functioning of the system. Proper preparation of the environment is crucial for optimizing performance, facilitating seamless data processing, and eliminating potential roadblocks.
1. Resource Allocation: Before setting up any data processing system, it is essential to allocate the appropriate resources to ensure smooth operations. This includes identifying and provisioning the necessary hardware and software components required for the desired level of processing capacity. Adequate storage, memory, and processing power need to be allocated to avoid bottlenecks and ensure efficient data processing.
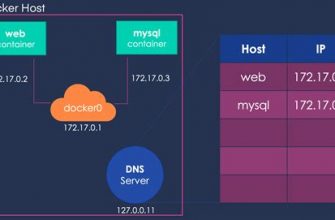
2. Network Configuration: The environment must be prepared by configuring the network to ensure seamless communication among the various components of the distributed data processing system. Proper network configuration involves setting up IP addresses, establishing reliable connections, and enabling efficient data transfer between nodes. A well-configured network infrastructure plays a vital role in promoting effective data distribution and parallel processing.
3. Configuring Dependencies: A crucial aspect of preparing the environment is configuring the necessary dependencies and software components that are essential for the smooth functioning of the data processing system. This may include installing and setting up Java, Apache Hadoop, Apache Spark, and other relevant frameworks or libraries. The correct installation and configuration of dependencies guarantee the proper execution of the data processing tasks.
4. Security and Access Control: Another crucial aspect of environment preparation involves implementing adequate security measures and access controls. This ensures the protection of data, prevents unauthorized access, and safeguards the integrity of the system. Setting up user authentication, encryption, and role-based access control mechanisms are essential steps in fortifying the environment against potential security threats.
5. Testing and Validation: Prior to deploying a distributed data processing system, rigorous testing and validation must be carried out to ensure that the environment is properly set up and functioning as expected. This involves executing test cases, verifying configuration settings, and validating the overall performance of the system. Thorough testing and validation help identify and rectify any issues or inconsistencies before going live.
By proactively preparing the environment for a distributed data processing system, organizations can ensure the smooth and efficient functioning of their data infrastructure. This sets the stage for successful implementation and utilization of powerful data processing technologies, enabling businesses to derive valuable insights and drive informed decision-making.
Deploying a Distributed Computing Environment with Containerization Technology

Containerization technology has revolutionized the deployment process of complex distributed computing environments by providing a lightweight and efficient solution. In this section, we will explore the process of deploying a high-performance computing cluster utilizing containerization technology.
- Understanding Containerization Technology
- Benefits of Containerization for Distributed Computing
- Introduction to Hortonworks Data Platform
- Exploring the Capabilities of Hadoop for Big Data Processing
- Containerizing Hortonworks Hadoop Cluster
- Orchestrating Containers Using Docker Compose
- Configuring Container Networking and Communication
- Scaling the Hortonworks Hadoop Cluster
- Monitoring and Troubleshooting
By gaining a deeper understanding of containerization technology and leveraging its advantages, organizations can effectively deploy and manage powerful distributed computing environments such as Hortonworks Hadoop cluster. This section will provide valuable insights and practical guidance on deploying and scaling your own containerized Hadoop cluster.
Configuring the Distributed Data Processing Environment
In this section, we will explore the essential steps to configure the distributed data processing environment for efficient data analysis and processing. The configuration process involves setting up the necessary components and optimizing the system parameters to ensure smooth and accurate execution of data-intensive tasks.
To start, we will customize the parameters of the distributed file system, which governs the storage and retrieval of data across the cluster. We will delve into optimizing the replication factor, block size, and other key file system properties to strike a balance between data redundancy and storage efficiency.
Next, we will focus on fine-tuning the processing framework that powers the distributed computing capabilities. This includes adjusting the memory allocation, parallelism settings, and resource management parameters to maximize the cluster's computational capacity and minimize the data processing time.
Additionally, we will explore the configuration options for enabling data compression techniques, such as Snappy, to minimize the storage footprint without compromising the data retrieval performance. We will also discuss the usage of data serialization frameworks, like Apache Avro, to enhance data interchangeability and compatibility among different components of the cluster.
Moreover, we will delve into the realm of workload management to ensure fair resource allocation and efficient task scheduling within the cluster. We will explore techniques such as scheduling queues, capacity planning, and application prioritization to optimize the utilization of cluster resources for various workloads.
Lastly, we will discuss security considerations and configuration options to protect the sensitive data stored and processed within the cluster. We will explore authentication, authorization, and encryption mechanisms to safeguard data integrity and prevent unauthorized access.
By the end of this section, you will have a comprehensive understanding of the configuration aspects critical to harnessing the full potential of your Hortonworks Hadoop cluster and ensuring optimal performance.
Testing and Verifying the System Configuration

In this section, we will demonstrate how to test and validate the setup of the Hadoop cluster on the Docker environment in the Windows operating system. The purpose of this verification process is to ensure that the installation and configuration of all components, services, and dependencies are functioning correctly in the clustered environment.
Step 1: Executing System Sanity Checks
Before proceeding with the cluster validation, it is crucial to perform a series of system sanity checks to ensure the proper functioning of the Docker containers, network connectivity, and system resources. These checks involve confirming the availability of required ports, verifying the Docker service and container status, and examining the resource utilization using monitoring tools or Docker commands.
Step 2: Testing Hadoop Cluster
In this step, we will execute a series of tests to verify the functionality and performance of the Hadoop cluster. This includes performing basic operations such as creating directories, uploading and retrieving files, as well as executing sample MapReduce jobs. These tests will help identify any potential issues with the cluster deployment and configuration, ensuring that data can be processed and stored effectively.
Step 3: Verification of Data Replication and High Availability
In this stage, we will focus on validating the data replication and high availability features of the Hadoop cluster. By creating and replicating data across multiple nodes, we can ensure that data redundancy and fault tolerance mechanisms are working as expected. Additionally, we will test the cluster's ability to gracefully handle node failure scenarios while maintaining data integrity.
Step 4: Performance Evaluation and Scalability
Lastly, we will assess the performance and scalability aspects of the Hadoop cluster. By executing benchmark tests and evaluating the cluster's ability to handle increasing workloads, we can gauge the system's efficiency and determine if any fine-tuning or optimization measures are required. This step is crucial in ensuring that the cluster is capable of meeting the organization's data processing and storage requirements.
By following these steps and conducting thorough testing and verification, we can ensure the successful installation and configuration of the Hadoop cluster on Docker in the Windows environment. This validation process provides the foundation for a reliable and efficient Big Data processing infrastructure.
[MOVIES] [/MOVIES] [/MOVIES_ENABLED]FAQ
What is Hortonworks Hadoop Cluster?
Hortonworks Hadoop Cluster is a distributed computing framework that allows for the storage and processing of large datasets across clusters of computers.
Why would I want to set up Hortonworks Hadoop Cluster on Docker in Windows?
Setting up Hortonworks Hadoop Cluster on Docker in Windows allows you to easily create and manage a virtualized environment for running Hadoop, without the need for installing and configuring the software directly on your machine.
What are the requirements for setting up Hortonworks Hadoop Cluster on Docker in Windows?
To set up Hortonworks Hadoop Cluster on Docker in Windows, you will need a Windows machine with Docker installed, sufficient system resources (RAM, CPU, storage) to run the cluster, and access to the internet to download necessary images and resources.
Can I run Hortonworks Hadoop Cluster on Docker on other operating systems?
Yes, you can run Hortonworks Hadoop Cluster on Docker on various operating systems including Linux and macOS, but the specific steps and configurations may differ.
What are the benefits of using Docker for setting up Hortonworks Hadoop Cluster?
Using Docker for setting up Hortonworks Hadoop Cluster provides several benefits such as isolation of resources, easy scalability, portability, and the ability to quickly spin up or tear down multiple containers for different components of the cluster.
What is the purpose of setting up Hortonworks Hadoop Cluster on Docker in Windows?
The purpose of setting up Hortonworks Hadoop Cluster on Docker in Windows is to create a virtualized environment that allows users to run Hadoop and its related tools on their Windows machines without the need for a dedicated physical cluster.